主页 | 产品介绍 | 下载 | 购买 | 技术支持 | 应用 | 论坛 | 用户评价 | 公司介绍 | 联系我们
|
|
||
|
主页 | 产品介绍 | 下载 | 购买 | 技术支持 | 应用 | 论坛 | 用户评价 | 公司介绍 | 联系我们 |
||
|
| ||
| 用于各种声音识别项目的声音监视与匹配应用程序接口 |
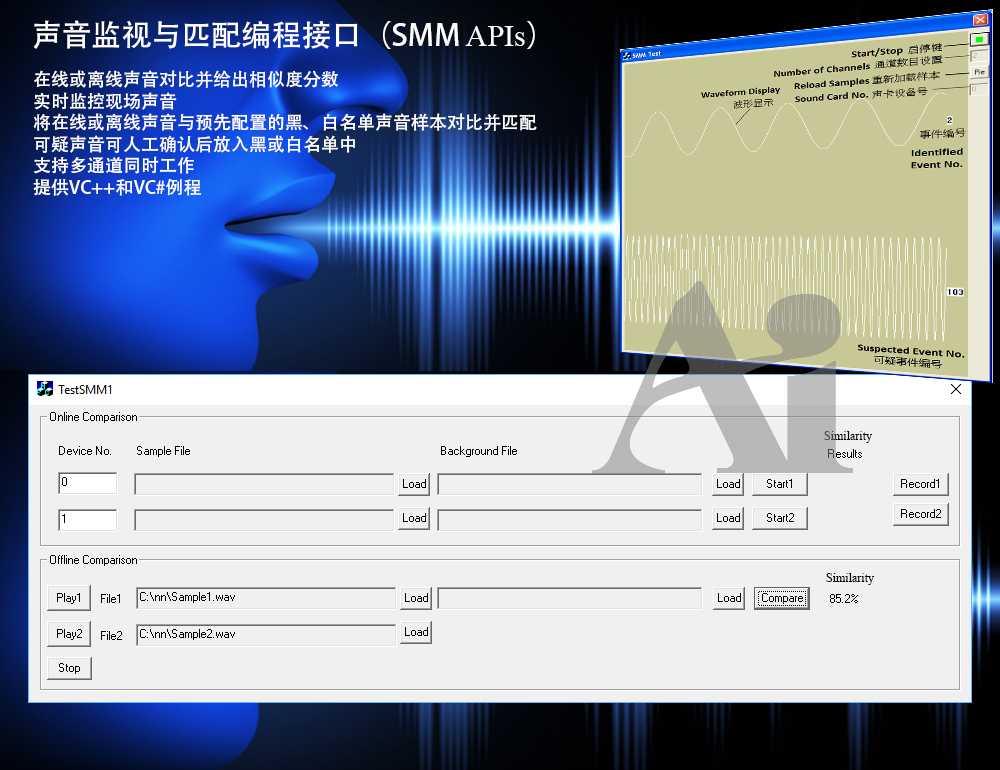 用于各种声音识别项目的声音监视与匹配应用程序接口 声音识别是人工智能(AI)的一个重要应用领域。市面上有多种声音识别技术存在,可用于语音识别、音乐识别、环境声音识别、动物声音识别、机器的气载声音或结构传导声音的识别等。从宏观上说,这些技术都包含信号预处理、特征提取和特征匹配/归类算法。但是,不同的声音类别或不同的具体应用所采用的声音识别技术在实施层面却是不同的。例如,目前市面上有一些不错的自动语音识别软件和应用程序接口,但是却无法直接用来进行动物声音识别。 特殊的声音识别应用通常需要定制编程。虚仪科技在此领域耕耘多年,已完成的项目包括: 1. 无人值守变电站16通道实时声音监视及正常音和异常音匹配归类(与正常音和异常音的样本比较) 2. 八音盒声音品质合格/不合格出厂检测(与标准声音样本比较) 3. 发声玩具声音品质合格/不合格出厂检测(与标准声音样本比较) 经多年研发并在多个实际项目的推动下,我们开发出一套声音识别应用程序接口以及演示这些接口的VC++和VC#例程。此应用程序接口称为声音监视与匹配应用程序接口,其功能简述如下: 1. 在线或离线声音对比并给出以百分比表示的相似度分数 2. 实时监测现场声音 3. 将在线或离线声音与预先配置的黑、白名单声音样本对比并匹配归类 4. 不属于当前黑、白名单的可疑声音可经人工确认后放入黑、白名单中 5. 支持多通道声卡,或多个单通道声卡 下面介绍的免费软件Sound-Similar (免费版) 就是采用此API开发的。有兴趣进一步了解详情者,请与我们联系。 最后,有些应用可能看起来需要用到复杂的声音识别技术,但其实只需正确配置Multi-Instrument即可实现所需功能。这里有个例子,请看视频:在一个受控环境中识别打火机的打火声音。 Sound-Similar (免费版) (下载) Sound-Similar (免费版) 是一个轻巧的工具软件,可用于测量两个具有线性PCM格式的WAV声音文件在听觉上的相似度。这种格式是WAV文件中最常见的。相似度以百分比0%~100%来表示。它不是通过对两个数字文件进行一个字节一个字节的对比而得,也不是通过对时域波形的形状进行对比而得,而是基于人的听觉感受,通过一系列的时域、频域和时频域分析得到的。测得的相似度可用于声音的归类以及基于听感的声音质量检测。 两个WAV文件可以具有不同的采样频率、不同的采样位数以及一个或两个通道的数据。如果是双声道信号,则对比中采用的是两个通道的平均值。声音的音量差别不会影响相似度的测量,除非音量小到足以影响所能感知到的声音品质。 不同类别的声音,例如语音、音乐、和环境声音,可能具有不同的频率范围。 Sound-Similar允许用户指定用于对比的频率范围以提高相似度测量的准确度。频率范围可以延伸到次声波或超声波范围。 有两种对比模式:(1)全长vs全长(Full Length vs Full Length),(2) 短文件的全长vs长文件的部分长度(Full Length of the Shorter vs Partial Length of the Longer)。这两种模式都允许两个文件有不同的时间长度。模式2可用于判断短文件是否是长文件中的一部分。如果是的话,给出其在长文件中的具体位置。声音长度应大于50毫秒,且应大于所设置的频率低限的倒数。声音长度的高限则只受制于电脑的内存大小。 本软件中的相似度评分算法是按常规用途来优化的。低于几个百分点的相似度通常表示两个声音完全不同,而从几个百分点到100%表示两个声音是相似的,只是相似程度不同。也就是说,Sound-Similar不仅可以用来进行声音归类,而且也可以用来检测声音跟标准样本对比后的质量差别。 Sound-Similar是用虚仪科技研发的Sound Monitoring and Matching (SMM) API 编写的。此API允许更加灵活的对比参数设置,并提供了更高级的选项,例如背景噪声滤除、短时噪声和失真检测、不同的评分方法等。 1. 稳定或准稳定的声音对比例子: (1) 双音频音DTMF的识别(阳性):DTMF-1-SR44100-16Bit-2s-Ideal.wav vs DTMF-1-SR44100-16Bit-2s-Noisy.wav 二者皆为2秒长的双音频音"1",包含697Hz和1209Hz,采样频率44.1kHz,采样位数16 bits。前者由Multi-Instrument的信号发生器直接数字生成,因而是理想的、无噪声的;而后者是由话筒录制从音响播放出来的声音获得的,因而含有较大的噪声。二者的音量差别大约是8 dB。下图显示的是二者的时域波形、频谱以及声谱的对比。由于Sound-Similar Free内部有抗噪设置,因此测得的相似度高达99.5%。结论是阳性(即:非假阴性)。 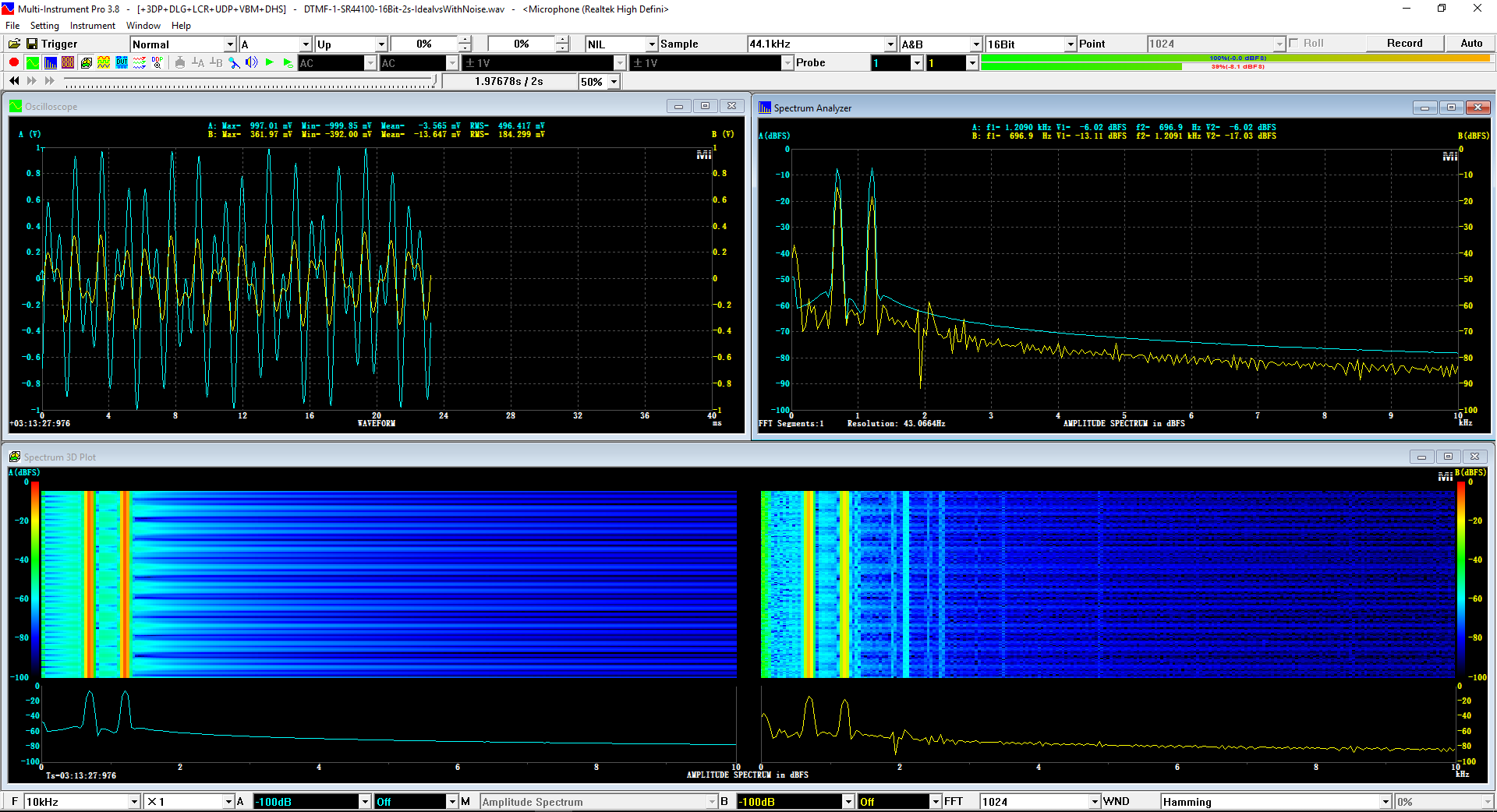 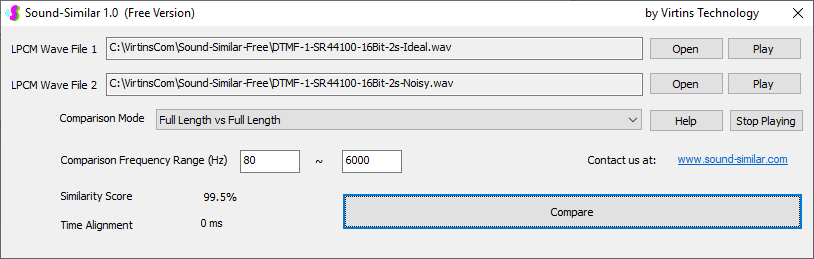 (2) 双音频音DTMF的识别(阴性):DTMF-2-SR44100-16Bit-2s-Ideal.wav vs DTMF-1-SR44100-16Bit-2s-Noisy.wav 前者为2秒长的双音频音"2",包含697Hz和1336Hz,采样频率44.1kHz,采样位数16 bits。后者为2秒长的双音频音"1",包含697Hz和1209Hz,采样参数与前者相同。前者由Multi-Instrument的信号发生器直接数字生成,因而是理想的、无噪声的;而后者是由话筒录制从音响播放出来的声音获得的,因而含有较大的噪声。二者的音量差别大约是8 dB。下图显示的是二者的时域波形、频谱以及声谱的对比。测得的相似度为12.1%,因此结论是阴性(即:非假阳性)。应当注意的是,各双音频音其实听起来都是比较相似的,如果两个不同的双音频音含有一个相同的频率成份,则相似度可升高到几十个百分点。但是,如果两个双音频音含有两个相同的频率成份(即:这两个双音频音是相同的),则它们的相似度将会非常接近100%。 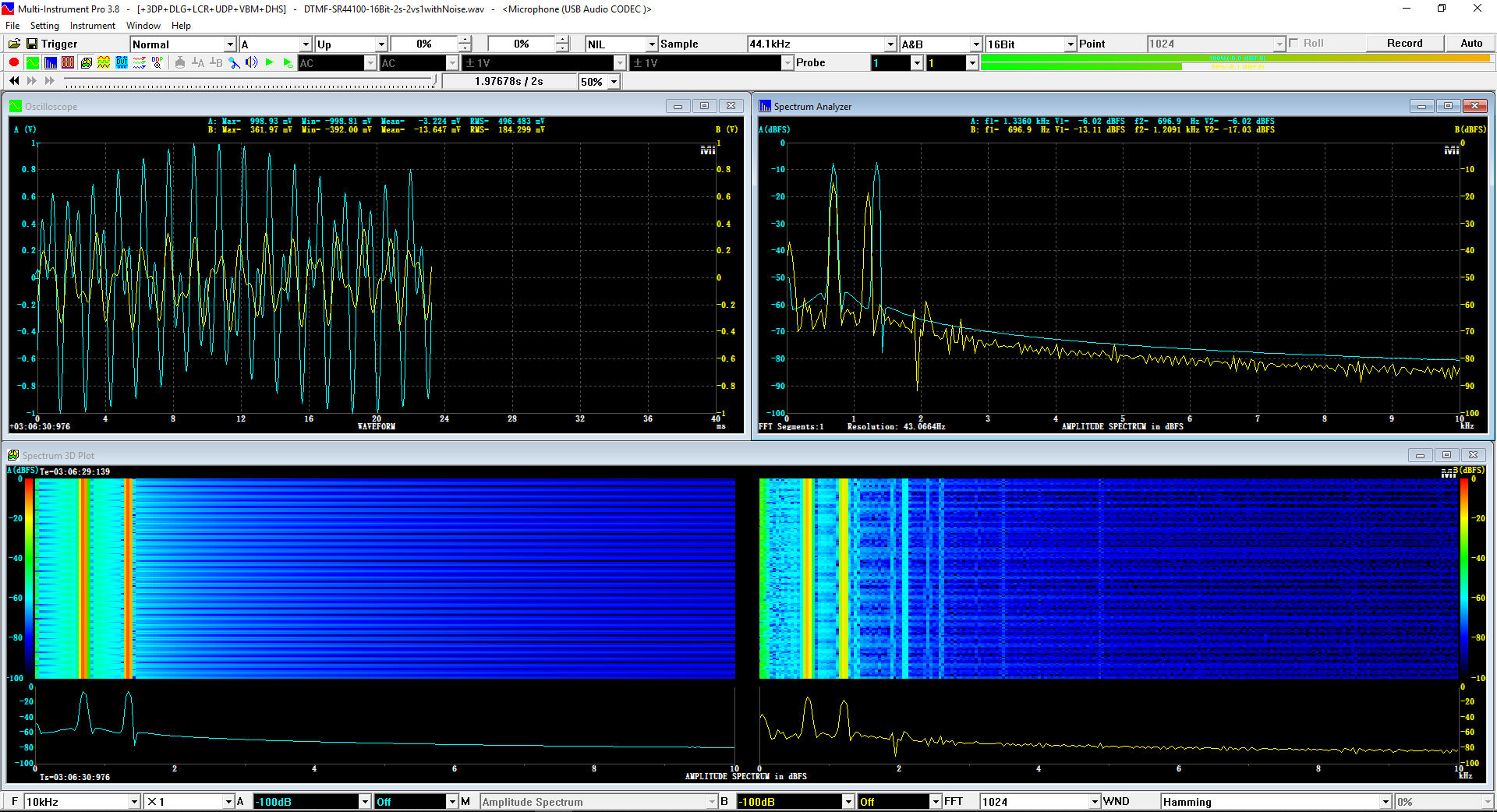 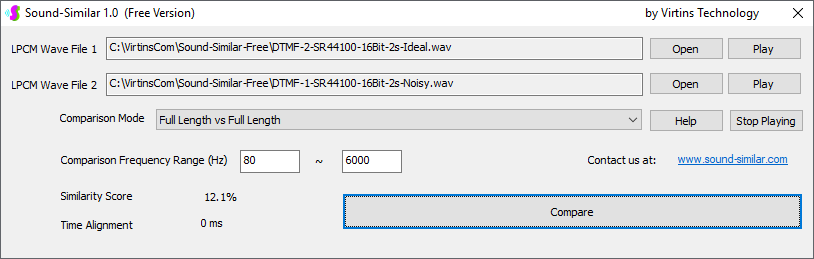 (3) 音量差别对相似度的影响:DTMF-1-SR44100-16Bit-2s-Ideal_-60dB vs DTMF-1-SR44100-16Bit-2s-Noisy.wav 此测试与上面的1(1)相似,只是这里的第一个文件的音量比1(1)的第一个文件小60dB(即:1/1000),或者说比这里的第二个文件小52dB。测得的相似度为96.6%,与1(1)的99.5%相比只下滑了少许,说明音量差别对相似度的影响极小。 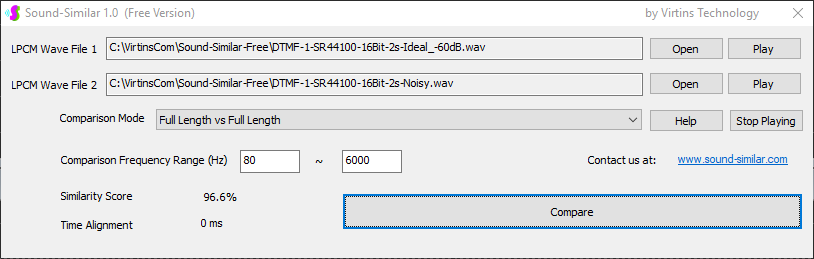 (4) 时间长度对相似度的影响:DTMF-1-SR44100-16Bit-10s-Ideal.wav vs DTMF-1-SR44100-16Bit-2s-Noisy.wav 此测试与上面的1(1)相似,只是这里的第一个声音的时间长度是10秒,是第二个声音的时间长度的5倍。测得的相似度为99.4%,与1(1)几乎完全一致。应当注意的是,这里的长文件在其整个长度内包含的是相同的稳定信号。 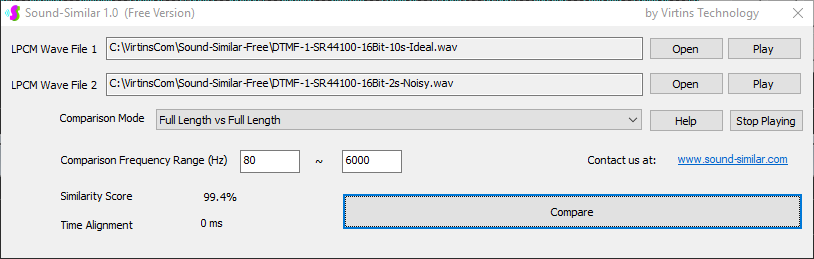 (5) 变电站声音识别(阴性):Substation-60Hz-High-Votage-Transformer-Sound-SR44100-16Bit-2s.wav vs Substation-60Hz-Partial-Discharge-Sound1-SR44100-16Bit-2s.wav 前者是2秒长的变电站高压变压器发出的声音,而后者是2秒长的变电站内出现的局部放电声音。前者比较稳定而后者则不太稳定。测得的相似度为0.6%,也就说本测试可以区别局部放电声与交流嗡声。应当注意的是,这里对比用的频率低限设置为30Hz,以将50Hz或60Hz的交流嗡声考虑在内。 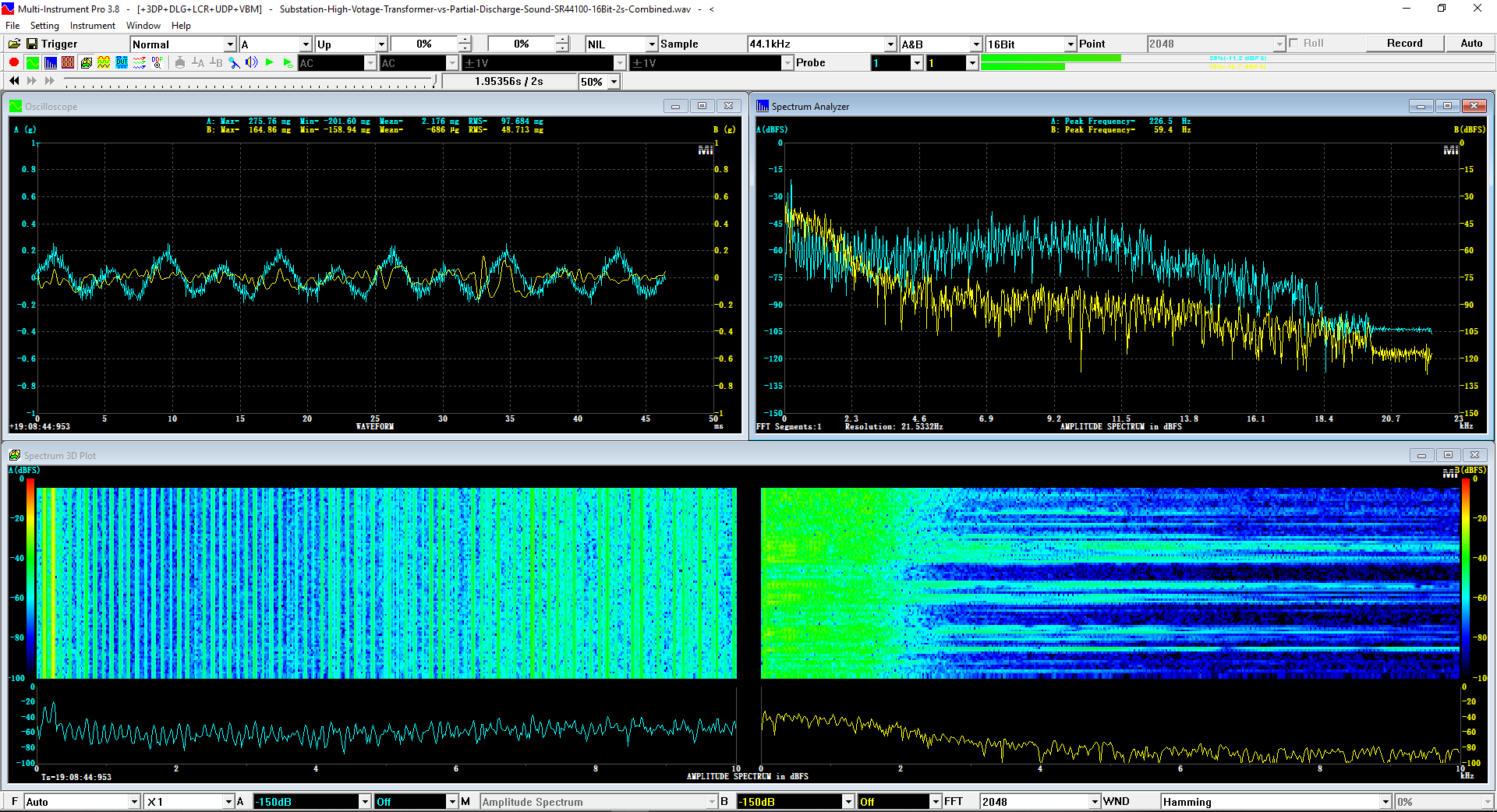 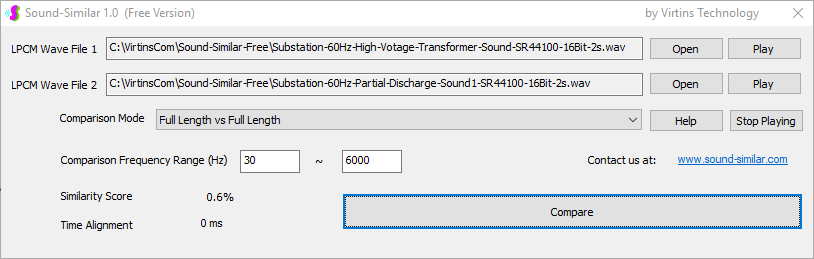 (6) 变电站声音识别(阳性):Substation-60Hz-Partial-Discharge-Sound1-SR44100-16Bit-2s.wav vs Substation-60Hz-Partial-Discharge-Sound2-SR44100-16Bit-2s.wav 二者皆为2秒长的变电站内的局部放电声,测得的相似度为84.5%,也就是说它们可以归类到同一类别。应当注意的是,这里对比用的频率低限设置为30Hz,以将50Hz或60Hz的交流嗡声考虑在内。 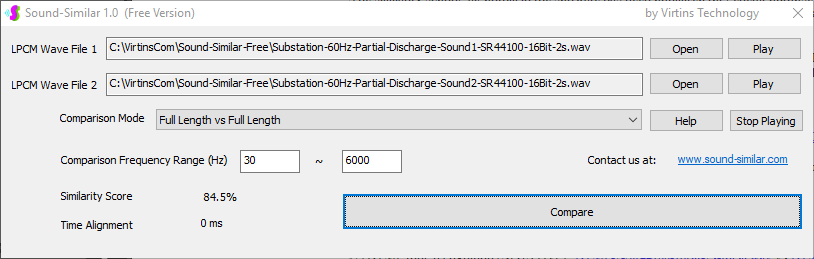 2. 非稳定声音对比例子: (1) 音乐识别1(阳性):Piano-1-1-SR44100-16Bit-10s.wav vs Piano-1-2-SR44100-16Bit-10s.wav 二者都是通过播放同样一段音乐录制的,只是录制采用的音响和话筒不同,背景噪声和回声也不同。测得的相似度为90.9%。 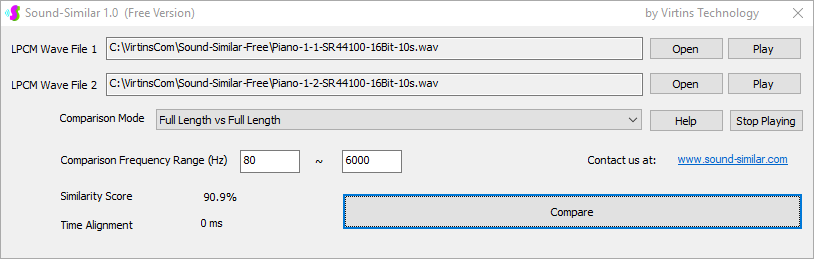 (2) 音乐识别2(阳性):Piano-2-1-SR44100-16Bit-10s.wav vs Piano-2-1-SR44100-16Bit-10s.wav 二者都是通过播放同样一段音乐录制的,只是录制采用的音响和话筒不同,背景噪声和回声也不同。测得的相似度为91.5%。 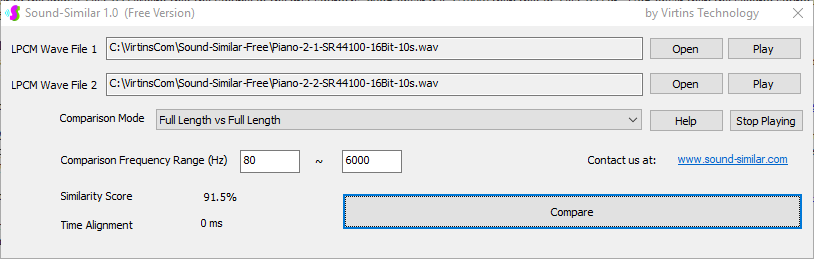 (3) 音乐识别(阴性):对上面的2(1)和2(2)中的音乐做交叉对比 i) Piano-1-1-SR44100-16Bit-10s.wav vs Piano-2-1-SR44100-16Bit-10s.wav:相似度为0.5% 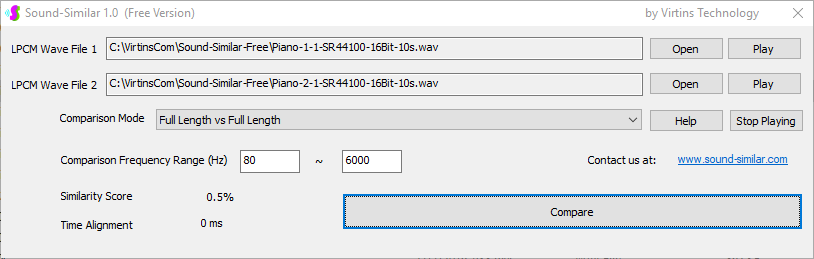 ii) Piano-1-1-SR44100-16Bit-10s.wav vs Piano-2-2-SR44100-16Bit-10s.wav:相似度为0.5% 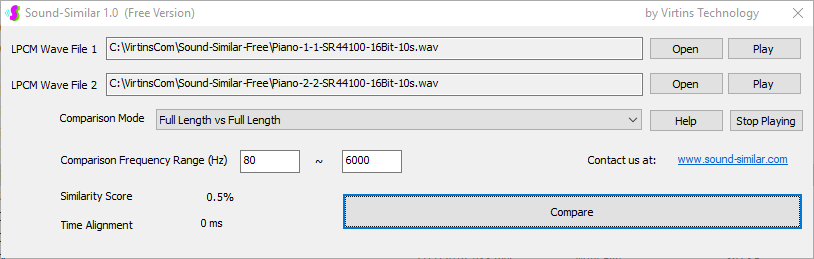 iii) Piano-1-2-SR44100-16Bit-10s.wav vs Piano-2-1-SR44100-16Bit-10s.wav:相似度为0.6% 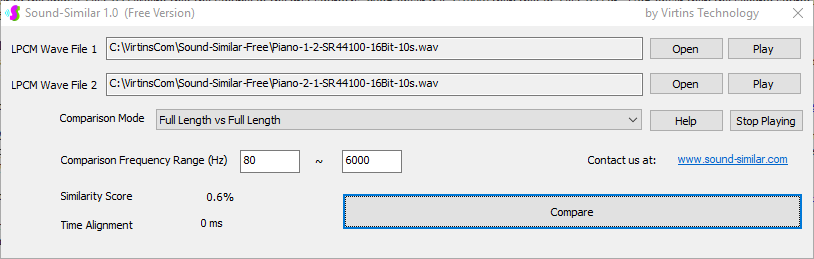 iv) Piano-1-2-SR44100-16Bit-10s.wav vs Piano-2-2-SR44100-16Bit-10s.wav:相似度为0.5%  (4) 歌曲识别1(阳性):Song-1-1-SR44100-16Bit-10s.wav vs Song-1-2-SR44100-16Bit-10s.wav 二者都是通过播放同样一段歌曲录制的,只是录制采用的音响和话筒不同,背景噪声和回声也不同。测得的相似度为71.9%。 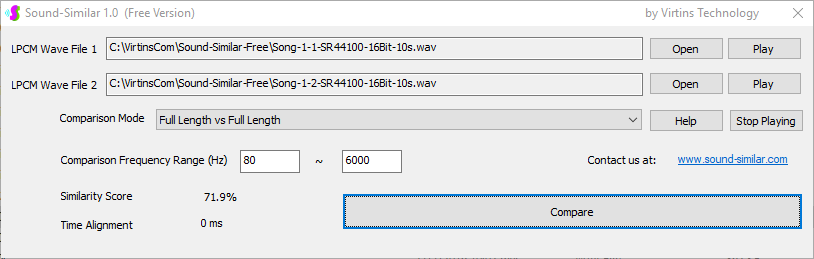 (5) 歌曲识别2(阳性):Song-2-1-SR44100-16Bit-10s.wav vs Song-2-2-SR44100-16Bit-10s.wav 二者都是通过播放同样一段歌曲录制的,只是录制采用的音响和话筒不同,背景噪声和回声也不同。测得的相似度为83.5%。 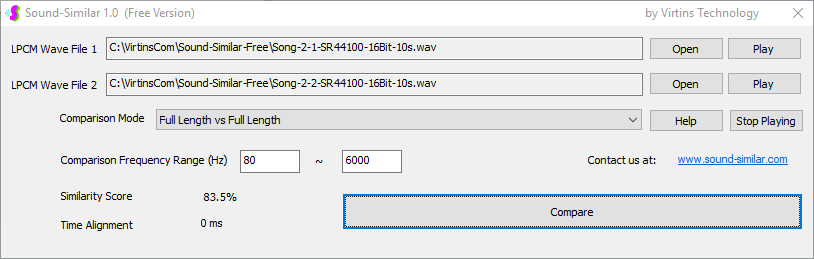 (6) 歌曲识别(阴性):对上面的2(4)和2(5)中的歌曲片段做交叉对比 i) Song-1-1-SR44100-16Bit-10s.wav vs Song-2-1-SR44100-16Bit-10s.wav:相似度为0.3% 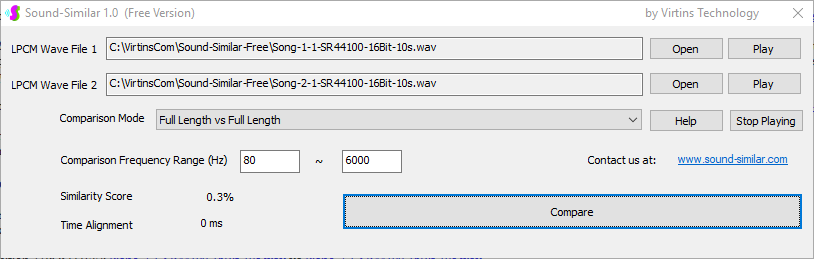 ii) Song-1-1-SR44100-16Bit-10s.wav vs Song-2-2-SR44100-16Bit-10s.wav:相似度0.2% 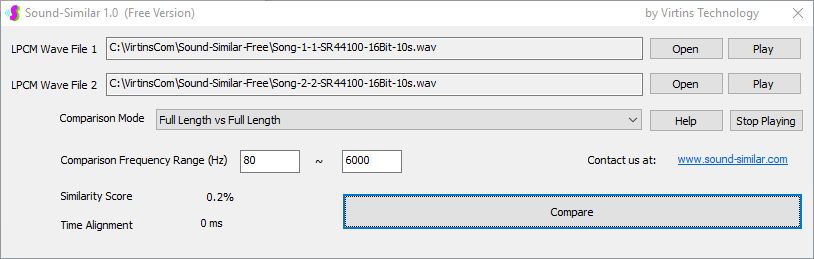 iii) Song-1-2-SR44100-16Bit-10s.wav vs Song-2-1-SR44100-16Bit-10s.wav:相似度0.2%  iv) Song-1-2-SR44100-16Bit-10s.wav vs Song-2-2-SR44100-16Bit-10s.wav:相似度0.3% 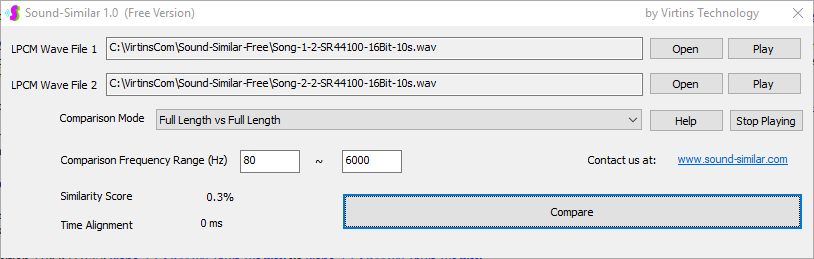 (7) 语音识别1(阳性):Speech-1-1-SR44100-16Bit-2s.wav vs Speech-1-2-SR44100-16Bit-2s.wav 二者都是通过播放同样一段语音("Because these two really sounds similar!")录制的,只是录制采用的音响和话筒不同,背景噪声和回声也不同。测得的相似度为80.5%. 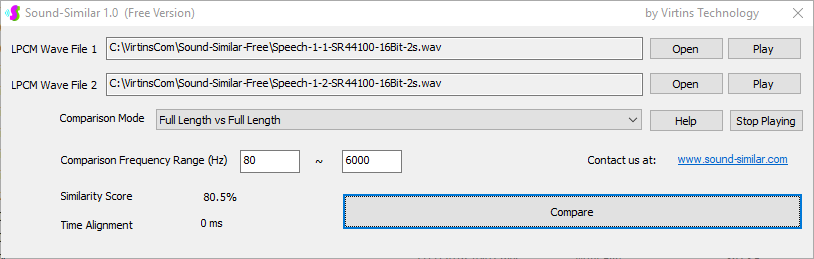 (8) 语音识别(相似性):Speech-1-1-SR44100-16Bit-2s.wav vs Speech-1-3-SR44100-16Bit-2s.wav 前者为语音"Because these two really sound similar!"而后者为语音"Because these two really sound different!",也就是说只有最后一个单词不同。测得的相似度为60.5%。 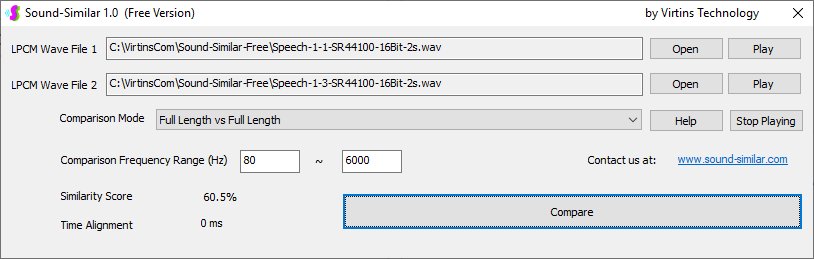 (9) 语音识别(相似性):Speech-1-1-SR44100-16Bit-2s.wav vs Speech-1-4-SR44100-16Bit-2s.wav 前者为语音"Because these two really sound similar!"而后者为语音"Because these two sound really similar!",也就是说只有两个单词的位置被互换了,相当于有两个单词不同。测得的相似度为9.7%。 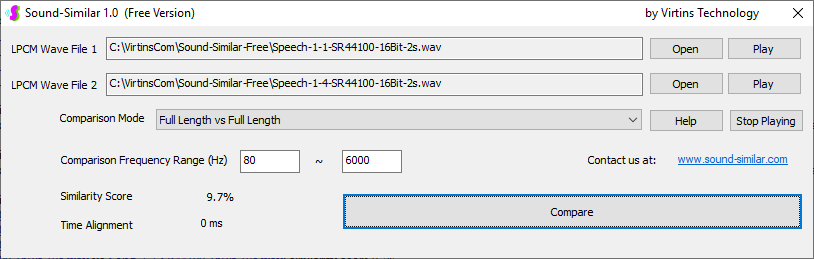 (10) 语音识别4 (相似性):Speech-1-1-SR44100-16Bit-2s.wav vs Speech-1-5-SR44100-16Bit-2s.wav 前者为语音"Because these two really sound similar!"而后者为语音"Because these two sound similar really!",也就是说只有三个单词的位置被交换了,相当于有三个单词不同。测得的相似度为1.4%。 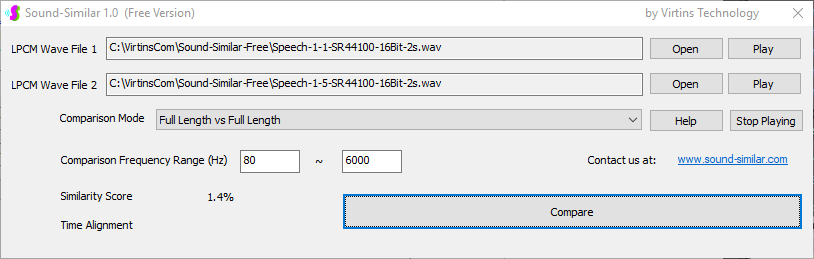 (11) 在长WAV文件中搜寻短WAV文件:Song-3-2-SR44100-16Bit-1s.wav in Song-3-1-SR44100-16Bit-20s.wav 录制二者所采用的音响和话筒不同,背景噪声和回声也不同。前者含有1秒长的歌曲片段,而后者含同一首歌曲的20秒长的片段。对比模式设置为"Full Length of the Shorter vs Partial Length of the Longer"。测试结果显示,第二个文件的14.477秒~15.477秒之间的声音与第一文件的声音相似,相似度为55.2%。 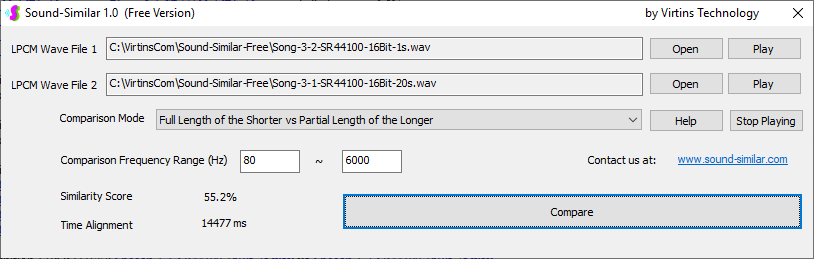 |
| 主页 | 产品介绍 | 下载 | 购买 | 技术支持 | 应用 | 论坛 | 用户评价 | 公司介绍 | 联系我们 | |
渝ICP备19012269号-1 渝ICP备19012269号-2

|